Retrieval models are often evaluated on partially-annotated datasets. Each query is mapped to a few relevant texts and the remaining corpus is assumed to be irrelevant. As a result, models that retrieve false negatives are punished in evaluation. Unfortunately, completely annotating all texts for every query is not resource efficient. In this work, we show that using partially-annotated data in evaluation can paint a distorted picture. We curate D-MERIT, Dataset for Multi-Evidence Retrival Testing, a passage retrieval evaluation set from Wikipedia, aspiring to contain all relevant passages for each query. Queries describe a group (e.g., “journals about linguistics”) and relevant passages are evidence that entities belong to the group (e.g., a passage indicating that Language is a journal about linguistics). We show that evaluating on a dataset containing annotations for only a subset of the relevant passages might result in misleading ranking of the retrieval systems and that as more relevant texts are included in the evaluation set, the rankings converge. We propose our dataset as a resource for evaluation and our study as a recommendation for balance between resource-efficiency and reliable evaluation when annotating evaluation sets for text retrieval.
D-MERIT comprises 1,196 queries, encompassing 60,333 evidence in total. On average, there are 50.44 evidence and 23.71 members per query. In the paper, we estimate our collection and identification coverage to be 94.5% and 84.7% respectively.
| # Members | Avg # Evidence | # Queries |
|---|---|---|
| 1-10 | 25.5 | 558 |
| 11-20 | 32.0 | 282 |
| 21-50 | 69.8 | 236 |
| 51-100 | 109.7 | 77 |
| 100+ | 281.2 | 43 |
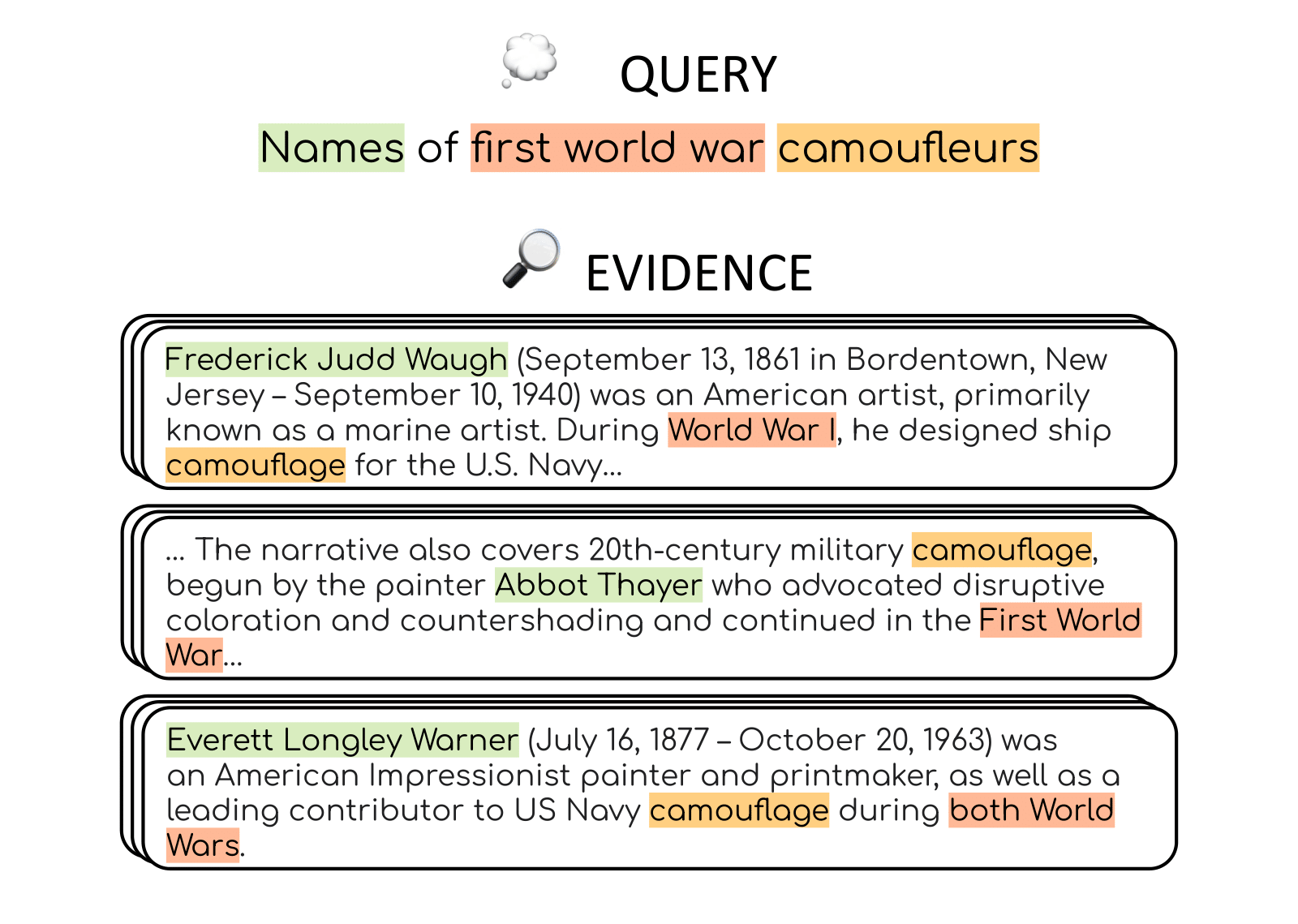
We choose evidence retrieval as our task as it naturally complements our need to collect queries with numerous relevant passages. Passages are considered relevant if they contain text that can be seen as evidence that some answer satisfies the query. Highlighted text corresponds to the query requirements: names (green), “First World War” (red), and “camouflage” (orange). A passage must match all requirements to be considered as evidence.
| Query | Member | Candidate | Evidence |
|---|---|---|---|
| names of Indian Marathi romance films | Sairat | Jeur | Jeur is a village in the Karmala taluka of Solapur district in Maharashtra state, India. Sairat, the controversial and highest-grossing Marathi film of all time based on the theme of forbidden love was set and shot in Jeur village. |
| names of National Wildlife Refuges in West Virginia | Ohio River Islands National Wildlife Refuge | Mill Creek Island | Mill Creek Island is a bar island on the Ohio River in Tyler County, West Virginia. The island lies upstream from Grandview Island and the towns of New Matamoras, Ohio and Friendly, West Virginia. It takes its name from Mill Creek, which empties into the Ohio River from the Ohio side in its vicinity. Mill Creek Island is protected as part of the Ohio River Islands National Wildlife Refuge. |
| Names of players on 1992 US Olympic ice hockey team | Dave Tretowicz | Dave Tretowicz | Dave Tretowicz (born March 15, 1969) is an American former professional ice hockey player. In 1988, he was drafted in the NHL by the Calgary Flames. He competed in the men's tournament at the 1992 Winter Olympics. |
| System | Recall@k | NDCG@k | MAP@k | R-precision | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 5 | 20 | 50 | 100 | 5 | 20 | 50 | 100 | 5 | 20 | 50 | 100 | ||
| SPLADE++ | 9.43 | 24.11 | 36.02 | 45.16 | 38.17 | 36.54 | 38.05 | 40.56 | 7.11 | 15.0 | 19.35 | 21.72 | 28.16 |
| SPLADEv2 | 7.82 | 21.21 | 33.29 | 43.34 | 32.09 | 31.43 | 33.78 | 37.00 | 5.74 | 12.20 | 16.03 | 18.27 | 24.82 |
| TCT-Colbert-Hybrid | 7.85 | 19.62 | 29.71 | 37.97 | 34.86 | 31.60 | 32.23 | 34.33 | 5.80 | 11.48 | 14.78 | 16.56 | 22.75 |
| bm25 | 6.65 | 17.46 | 27.54 | 35.76 | 28.93 | 27.20 | 28.62 | 31.13 | 4.76 | 9.76 | 12.83 | 14.61 | 20.86 |
| RetroMAE-Hybrid | 7.30 | 17.48 | 25.95 | 32.85 | 33.95 | 29.21 | 29.19 | 30.82 | 5.71 | 10.63 | 13.14 | 14.48 | 20.12 |
| RetroMAE | 7.03 | 16.62 | 24.78 | 31.61 | 32.71 | 27.98 | 27.94 | 29.61 | 5.47 | 10.05 | 12.38 | 13.66 | 19.29 |
| TCT-Colbert | 6.27 | 15.44 | 23.59 | 30.95 | 29.31 | 25.73 | 26.08 | 27.95 | 4.58 | 8.64 | 11.02 | 12.39 | 18.02 |
| CoCondenser-Hybrid | 5.28 | 14.81 | 24.25 | 32.88 | 22.13 | 21.87 | 23.96 | 26.89 | 3.41 | 6.82 | 9.10 | 10.63 | 16.78 |
| QLD | 5.49 | 13.96 | 23.56 | 31.96 | 24.54 | 21.71 | 23.63 | 26.55 | 3.77 | 7.07 | 9.51 | 11.13 | 16.56 |
| CoCondenser | 4.87 | 13.75 | 23.02 | 31.52 | 20.71 | 20.42 | 22.64 | 25.54 | 3.14 | 6.20 | 8.35 | 9.77 | 15.69 |
| Unicoil | 4.47 | 10.95 | 17.27 | 23.28 | 20.86 | 17.96 | 18.70 | 20.49 | 3.25 | 6.05 | 7.72 | 8.83 | 13.19 |
| DPR | 3.90 | 9.62 | 15.99 | 21.72 | 18.51 | 15.90 | 16.64 | 18.41 | 2.63 | 4.48 | 5.67 | 6.37 | 10.89 |
We assume a single annotation setup, and find that sampling random evidence does lead to reliable results, but such approach is not feasible in scale. To depict a realistic scenario, we also explore 4 other sampling approaches: popular, shortest, longest passage, and system-based (think TREC). For these, the error rate is much higher, which significantly affects the ranking of the models, and illustrates that in such cases, the single-relevant setting is unreliable.
| Selection | Tau-similarity | Error-rate (%) |
|---|---|---|
| Random | 0.936 | 3.20 |
| Most popular | 0.696 | 15.10 |
| Longest | 0.545 | 22.75 |
| Shortest | 0.696 | 15.10 |
| System-based | 0.616 | 19.20 |
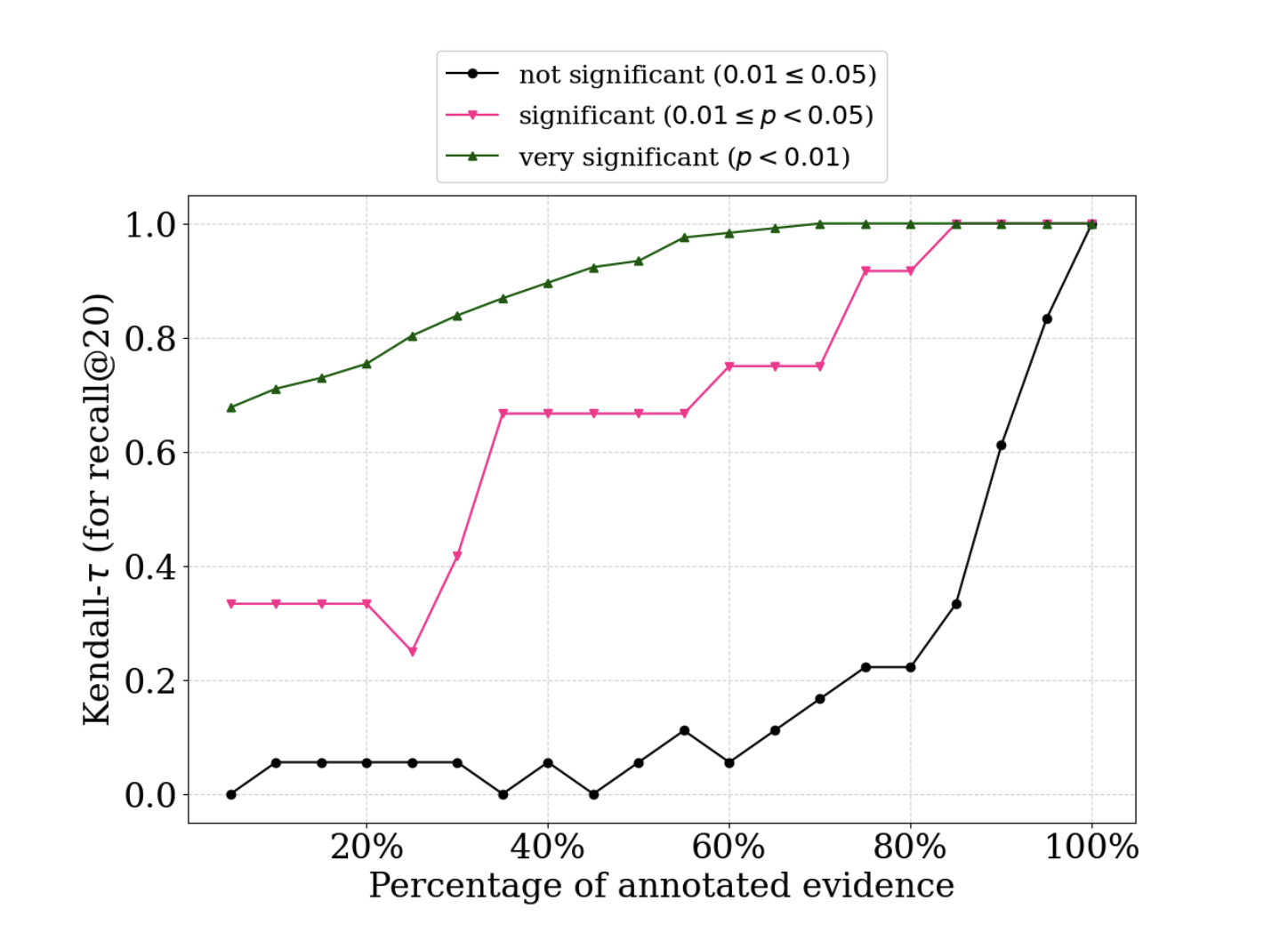
We evaluate 12 systems by increasing annotations in increments of 10%, and find that if the difference in performance between a pair of systems is large, around 20% of the annotations we collected suffice to obtain the correct ranking of systems. However, if the systems are close in performance, almost all annotations are needed.
@misc{rassin2024evaluating,
title={Evaluating D-MERIT of Partial-annotation on Information Retrieval},
author={Royi Rassin and Yaron Fairstein and Oren Kalinsky and Guy Kushilevitz and Nachshon Cohen and Alexander Libov and Yoav Goldberg},
year={2024},
eprint={2406.16048},
archivePrefix={arXiv},
primaryClass={id='cs.IR' full_name='Information Retrieval' is_active=True alt_name=None in_archive='cs' is_general=False description='Covers indexing, dictionaries, retrieval, content and analysis. Roughly includes material in ACM Subject Classes H.3.0, H.3.1, H.3.2, H.3.3, and H.3.4.'}
}